



hive默认建表存储格式
默认值与可选值
- hive.default.fileformat
- 默认值: TextFile
- 可选值:TextFile,SequenceFile,RCfile,ORC,Parquet
spark-sql测试 --hiveconf
## 1.进入spark-sql
spark-sql --hiveconf hive.default.fileformat=parquet
## 2.创建表并插入数据
create table hudi.person2(id bigint,name string);
insert into table hudi.person2 values(1,'zs'),(2,'ls');
select * from hudi.person2 limit 10;
## 3.确认建表格式是否为parquet,存储格式是否显示
show create table hudi.person2;
## 4.查看hdfs目录确认文件结构
spark-sql测试 set
## 1.进入spark-sql
spark-sql
## 2.设置默认存储格式为 Parquet
set hive.default.fileformat=parquet;
## 开启压缩
set spark.sql.parquet.compression.codec=gzip;
## 3.创建表并插入数据
create table hudi.person3(id bigint,name string,job string);
insert into table hudi.person3 values(1,'zs,aa分隔符:^_^','doctor'),(2,'ls','migrant workers');
select id,job from hudi.person3 limit 10;
## 4.确认建表格式是否为parquet,存储格式是否显示
show create table hudi.person3;
## 5.查看hdfs目录确认文件结构
关于spark存储格式与压缩的设置
- ORC
- 1.建表时在TBLPROPERTIES中增加属性"orc.compress"="snappy",需要对每张表进行设置
- 2.设置hive参数hive.exec.orc.default.compress=snappy,针对hive全局设置的,比较方便
- Parquet,Hive Parquet默认不采用压缩算法
- 1.建表时在TBLPROPERTIES中增加属性"orc.compress"="snappy",需要对每张表进行设置
- 2.spark内执行
-- 优先级从上往下,通常只用第一个 set spark.sql.parquet.compression.codec=gzip; set parquet.compression=snappy; set compression=gzip;
知识点
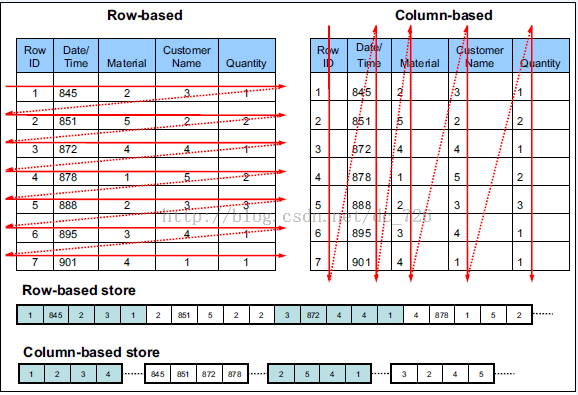
列式存储
相对于关系数据库中通常使用的行式存储,在使用列式存储时每一列的所有元素都是顺序存储的。由此特点可以给查询带来如下的优化:
- 查询的时候不需要扫描全部的数据,而只需要读取每次查询涉及的列,这样可以将I/O消耗降低N倍,另外可以保存每一列的统计信息(min、max、sum等),实现部分的谓词下推。
- 由于每一列的成员都是同构的,可以针对不同的数据类型使用更高效的数据压缩算法,进一步减小I/O。
- 由于每一列的成员的同构性,可以使用更加适合CPU pipeline的编码方式,减小CPU的缓存失效。
Parquet存储格式
Apache Parquet是Hadoop生态圈中一种新型列式存储格式,它可以兼容Hadoop生态圈中大多数计算框架(Mapreduce、Spark等),被多种查询引擎支持(Hive、Impala、Drill等),并且它是语言和平台无关的。
文件结构
Parquet文件是以二进制方式存储的,是不可以直接读取和修改的,Parquet文件是自解析的,文件中包括该文件的数据和元数据。在HDFS文件系统和Parquet文件中存在如下几个概念:
- HDFS块(Block):它是HDFS上的最小的副本单位,HDFS会把一个Block存储在本地的一个文件并且维护分散在不同的机器上的多个副本,通常情况下一个Block的大小为256M、512M等。
- HDFS文件(File):一个HDFS的文件,包括数据和元数据,数据分散存储在多个Block中。
- 行组(Row Group):按照行将数据物理上划分为多个单元,每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,Parquet读写的时候会将整个行组缓存在内存中,所以如果每一个行组的大小是由内存大的小决定的。
- 列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。不同的列块可能使用不同的算法进行压缩。
- 页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
通常情况下,在存储Parquet数据的时候会按照HDFS的Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。Parquet文件的格式如下图所示。
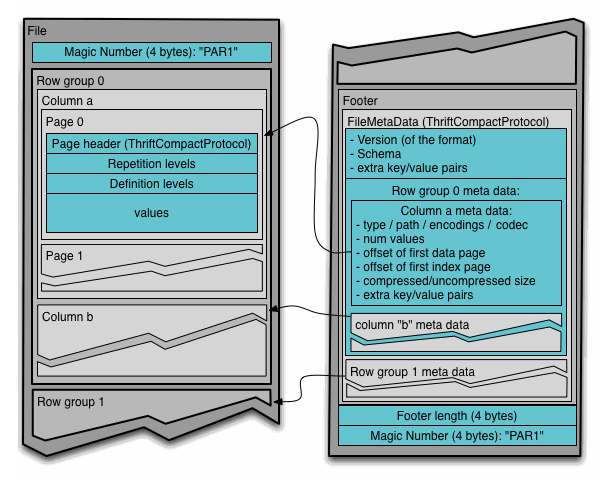
上图展示了一个Parquet文件的结构,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length存储了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和当前文件的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页,但是在后面的版本中增加。
ORC文件格式
ORC文件格式是一种Hadoop生态圈中的列式存储格式,它的产生早在2013年初,最初产生自Apache Hive,用于降低Hadoop数据存储空间和加速Hive查询速度。和Parquet类似,它并不是一个单纯的列式存储格式,仍然是首先根据行组分割整个表,在每一个行组内进行按列存储。ORC文件是自描述的,它的元数据使用Protocol Buffers序列化,并且文件中的数据尽可能的压缩以降低存储空间的消耗,目前也被Spark SQL、Presto等查询引擎支持,但是Impala对于ORC目前没有支持,仍然使用Parquet作为主要的列式存储格式。2015年ORC项目被Apache项目基金会提升为Apache顶级项目。
文件结构
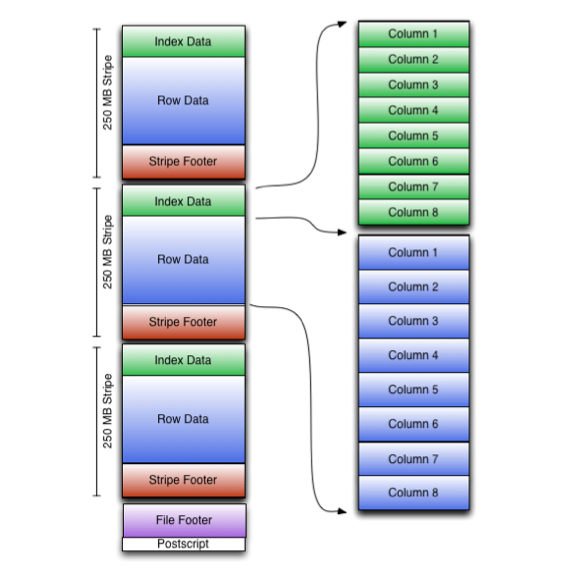
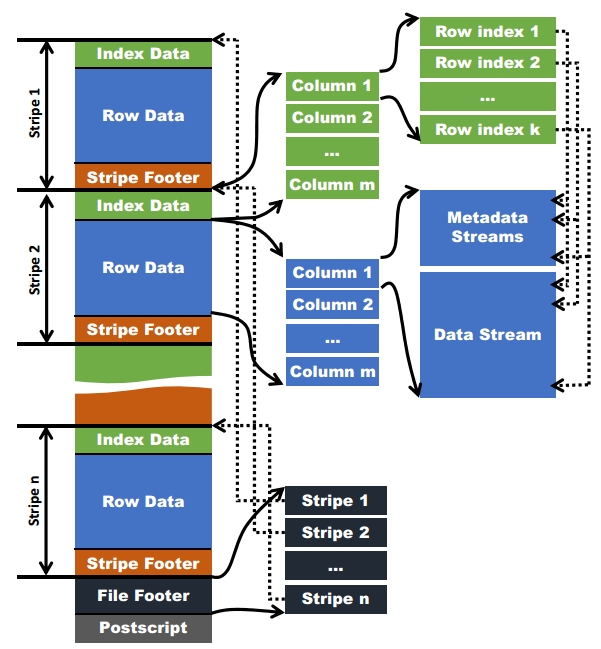
和Parquet类似,ORC文件也是以二进制方式存储的,所以是不可以直接读取,ORC文件也是自解析的,它包含许多的元数据,这些元数据都是同构ProtoBuffer进行序列化的。ORC的文件结构入图6,其中涉及到如下的概念:
- ORC文件:保存在文件系统上的普通二进制文件,一个ORC文件中可以包含多个stripe,每一个stripe包含多条记录,这些记录按照列进行独立存储,对应到Parquet中的row group的概念。
- 文件级元数据:包括文件的描述信息PostScript、文件meta信息(包括整个文件的统计信息)、所有stripe的信息和文件schema信息。
- stripe:一组行形成一个stripe,每次读取文件是以行组为单位的,一般为HDFS的块大小,保存了每一列的索引和数据。
- stripe元数据:保存stripe的位置、每一个列的在该stripe的统计信息以及所有的stream类型和位置。
- row group:索引的最小单位,一个stripe中包含多个row group,默认为10000个值组成。
- stream:一个stream表示文件中一段有效的数据,包括索引和数据两类。索引stream保存每一个row group的位置和统计信息,数据stream包括多种类型的数据,具体需要哪几种是由该列类型和编码方式决定。
在ORC文件中保存了三个层级的统计信息,分别为文件级别、stripe级别和row group级别的,他们都可以用来根据Search ARGuments(谓词下推条件)判断是否可以跳过某些数据,在统计信息中都包含成员数和是否有null值,并且对于不同类型的数据设置一些特定的统计信息。